

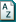

Understand the key concepts
This topic introduces key concepts that will help you to get up and running in NVivo.
In this topic
- Sources
- Coding and nodes
- Node classifications (to manage demographic attributes for case coding)
- Source Classifications (to manage bibliographical data)
Sources
In NVivo, sources include the materials you want to analyze and your ideas about them. Here are some examples of the sources you might work with in your project:
Refer to About Sources for detailed information about the types of sources you can import and Bring in your sources and get organized for ideas about how you can prepare and manage your sources.
 Top
of Page
Top
of PageCoding and nodes
You code your sources to gather material about a topic and store it in a container called a node.
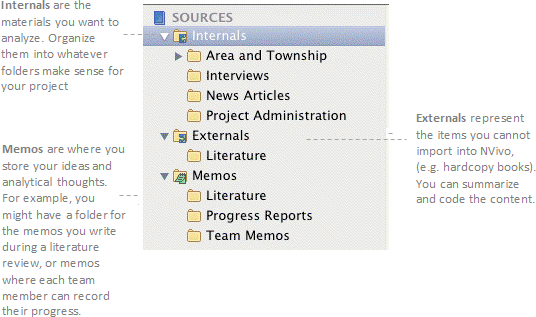
As you explore your sources, you can select content and code it at a node. For example, while working through your interviews you find that a number of participants talk about the natural environment—code each occurrence at the node Natural Environment.
When you open the node, you can see all the references in one place—allowing you to reflect on the topic, develop your ideas, compare attitudes and discover patterns:

Organizing your nodes is also an important part of the analytical process. As you catalogue your nodes in a hierarchy, you can refine your thoughts and draw connections between themes. For example, since the themes of Natural Environment and Water Quality are related, you might organize them like this:
-
Natural Environment
-
Habitat
-
Landscape
-
Water quality
Refer to About Coding for information on ways to code (along with links to detailed instructions).
For coding strategies and ideas, refer to Code sources and manage nodes.
Node classifications (to manage demographic attributes for case coding)
In the course of your research, you may want to make comparisons based on:
-
The demographic attributes of your participants (for example, you may want to compare attitudes based on gender or age).
-
The attributes of places, organizations or other entities (for example, you could compare how issues are handled in large and small schools).
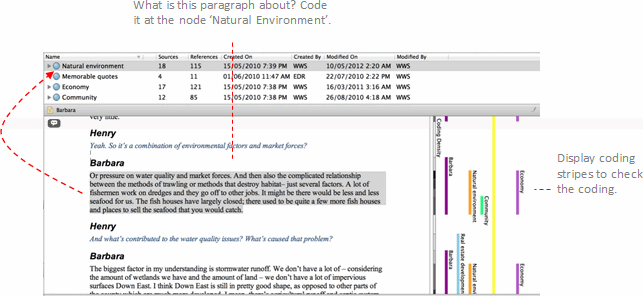
To make these kinds of comparisons, you need to setup
node classifications. For example, to gather demographic information about
interview participants you could:
Refer to Create node classifications for detailed instructions.
Source Classifications (to manage bibliographical data)
You can use source classifications to manage the bibliographical attributes of your sources. For example, if you work with articles you could:

Setting up source classifications also facilitates the use of queries and visualizations—for example, you could use a matrix coding query to see if a theme is prevalent across various types of sources (is a theme appearing in interviews but not in journal articles?).